Python искусственный интеллект Dbias Канада Индия Китай Австралия Google
Пакет был совместно разработан исследователями из Канады, Индии, Китая и Австралии.

Система, названная Dbias, использует различные технологии машинного обучения и базы данных для создания трехэтапного кругового рабочего процесса, который исправляет текст до тех пор, пока он не станет объективным или нейтральным.
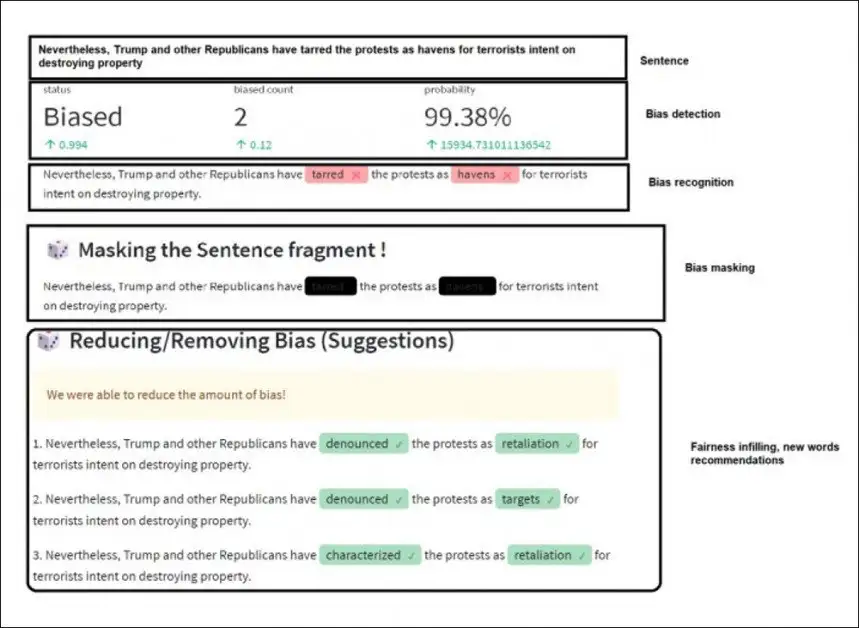
Текст новостного фрагмента, идентифицированный как “предвзятый”, преобразуется Dbias в более нейтральную версию.
Система представляет собой автономный пайплайн, способный выполнять многоразовые задания. Пакет можно установить через Pip от Hugging Face и интегрировать его в существующие проекты в качестве дополнительного этапа, дополнения или плагина.
Похожая система от Google Docs подверглась критике из–за отсутствия возможности настройки. У Dbias нет такой проблемы – ее можно обучить на нужном наборе новостей, создавая индивидуальные рекомендации для преобразования текста. Основное отличие Dbias от других похожих систем заключается в том, что он сам изменяет текст, делая его более нейтральным – пользователю не нужно заменять слова и выражения, ИИ сделает всю работу за него.

Концепт архитектуры рабочего процесса Dbias.
Рабочий процесс системы состоит из трех этапов:
Обнаружение предвзятости в тексте. Для этого Dbias использует пакет DistilBERT – оптимизированную нейросетевая модель–трансформер от Google, на которой строится большинство инструментов автоматической обработки языка. Для данного проекта DistilBERT был дополнительно обучен с использованием набора данных Media Bias Annotation (MBIC). MBIC состоит из новостных статей, взятых с Huffington Post, USA Today и MSNBC. Исследователи самостоятельно расширили набор данных, чтобы система могла выявлять предвзятость, связанную с расовой/этнической принадлежностью, образованием, языком, религией и полом.
Распознавание необъективных слов и выражений с помощью Named Entity Recognition (NER).
Устранение предвзятости. На этом этапе система использует маскированное языковое моделирование (MLM) для устранения необъективных слов и выражений. При необходимости, весь текст, который был получен в результате этого этапа, можно пропустить через систему еще несколько раз, пока не будет сгенерировано несколько подходящих слов и выражений.
Система была создана и обучена на базе Google Collab Pro с использованием видеоускорителя NVIDIA P100 с 24 ГБ видеопамяти. Размер батча (количество обучающих примеров за одну итерацию) был равен 16. На данный момент у системы есть две метки для текстов – biased и unbiased (предвзятый и непредвзятый).